[Deep Learning] RNN (Recurrent Neural Network), Trnasformer
RNN (Recurrent Neural Network)
CNN 과는 다르게 주어지는 입력 자체가 sequenial 하다는 것이다.
Sequential Model
Sequential 데이터는 언제 끝날 지 모른다.
- 이전 데이터가 들어왔을 때 다음을 예측한다.
- Autoregressive Model
- 과거의 몇개의 정보만을 현재에 의존 시킬 것인가를 결정한다.
- Markov model(first-order autoregressive model)
- Markov 식을 사용하여 바로 하나 이전 정보만을 사용한다.
- joint distribution의 표현이 쉬워진다.
- Latent autoregressive Model
- 중간에 hidden state를 두고 과거의 정보를 요약해서 저장한다.
- 과거 하나의 hidden state만 참고하여 다음을 예측한다.
Recurrent Neural Network
만약 사람이 5초 밖에 기억 하지 못한다면 무슨일이 발생할까?
RNN도 마찬가지로 이전 5개의 정보만 알 수 있다면 문장이든 sequential 한 데이터를 파악 하는데 어려움이 있을 것이다. -> LSTM
RNN의 문제점, 이전 네트워크 정보를 곱하고 time이 커질수록 엄청 연산이 커진다.
- 활성화 함수로 sigmoid를 사용하면 h0의 정보를 계속 곱하고 스쿼싱 하게되면 값이 죽어 버린다.(Vanishing)
- ReLU를 사용하게 된다면 W를 n번 곱하게 되면 시간이 지날 수록 엄청 커져 버리게 된다 (exploding gradient)
LSTM(Long Short Term Memory)
Core Idea
- cell state time stamp t까지의 데이터를 요약한다.
- 어떻게 중요데이터와 안좋은 데이터를 조작 하는지.
-
Forget Gate - x 와 이전 히든 정보를 곱하고 연산을 통해 버릴 것을 정한다.
-
Input Gate - x 와 이전 히든 정보를 곱사고 연산을 하여 중요한 정보를 cell state에 저장한다.(cell state candidate를 결정)
-
Update cell - Input Gate 를 통과한 cell state candidate후보와 이전 cell state 정보 Forget Gate를 통과한 정보를 통해 cell을 업데이트 한다.
-
Output Gate - 업데이트된 cell state를 사용하여 아웃풋을 만든다.
GRU (Gated Recurrent Unit)
- 특이한 점은 게이트가 두개인다.
- cell 스테이트가 없고, Hidden state만으로 모든것을 한다.
lstm 에서 안나오는 성능이 gru에서 나오기는 하지만 transformer 가 나오면서 요즘 lstm, gru 둘 다 잘 사용하지 않는다.
Tranasformer
sequential model(lstm, gru등) 의 한계를 해결하기 위해 등장한 Transformer에 대해 알아보자.
Trnasformer 소개
- Attention이라는 구조를 적용한 첫 모델이다.
- sequence가 주어지면 다른 sequence로 바꾸는 것이다.
- 한번에 여러개의 단어를 encoder에 들어가 처리가능한 구조이다.
중요 이해점.
- 어떻게 여러개의 단어를 encoder에서 처리가능한지?
- 인코더에서 디코더로 어떻게 데이터를 보낼지.
- 디코더가 어떻게 출력을 생산하는지.
먼저 첫번째를 이해해보자.
- Self-Attention은 Transformer의 토대이다.
문제를 푼다고 가정하고 순서를 알아보자.
- 각 단어의 특정 숫자의 벡터로 변환한다.
- Self-Attention은 입력 x들을 각각 개별의 z 벡터로 내보내주고 이때 z1 벡터는 x1뿐만 아니라 x2, x3 모든 input 벡터를 고려하여 결정된다.
- feed-forward는 그냥 개별로 아웃풋을 출력하고 모든 input을 고려하지 않는다.
”The animal didn’t cross the street because it was too tired” 라는 문장이 주어졌다고 가정해 보자.
여기서 it은 무엇을 가르키는지 알아야 할 것이다.
Self-Attention은 여기서 it 이 어느것을 가르키는지(무엇과 관계가 가장 깊은지)를 계산한다.
Self-Attention in Detail
Thinking 과 Machines 두가지 인풋이 들어왔을때의 과정을 보고 자세히 알아보자.
- 한 단어에 대하여 input과 Embedding벡터를 이용하여 Queries, Keys, Values 세가지 벡터를 만들어 낸다.
- Score를 계산한다. score는 query vector와 key벡터의 dot product(내적)으로 구해진다. 여기서 주의할 점은 thinking을 구할 때 다른 부분의 score도 위의 식처럼 구해야 한다.
- 스코어 벡터를 normalize 해주고 스코어에 \(d_k\)로 나누어 준다.
- 그리고 normalized score를 softmax를 취해준다.
- softmax를 취해준 것에 value를 곱하여 계산
- value vector의 합의 weighted 를 sum에 저장한다.
우리에겐 행렬이 있으니 Matrix를 이용하여 해결해보자.
- 먼저 Query, Key, Value 행렬을 계산해 주어야 한다.
- 이를 위해 WQ,WK,WV라는 훈련된 weight metrics를 통해 계산해준다.
- 마지막으로 위의 식을 이용하여 self-attention layer의 아웃풋을 계산한다.
- pytorch 를 이용해 1,2줄이면 계산 가능하다.
- value vector의 차원과 q,k벡터의 크기는 달라도 된다.
Multi-headed attention(MHA)
- 앞서 소개한 attention을 여러번 하는 것이다.
- 8개의 head를 사용했다면 8개의 다른 encoded vector set이 나온다.
- 하지만 다음 attention layer의 input으로 들어가기 위해서는 차원을 맞춰 줘야 한다.
- 위 그림에서는 Thinking과 Machines이 합쳐져 2x4로 표현된것이 2x3인 8개의 encoded vector가 나왔다.
- 이것을 원래 2x4의 형태로 맞춰 주기 위해 8개으 vector를 concatenate하고 W0 벡터를 통해 dimension을 맞춰준다.
The Residuals
- Self-Attention을 거쳐 나온 데이터 z 들과 임베딩된 x 데이터들이 Add & Normalize layer를 거친다.
-
반복적으로 Feed Forward layer 와 Add & Normalize 를 한번더 거쳐 Decoder로 전달된다.
- 다음은 ENCODER와 DECODER의 흐름이다.
최종 형태.
 https://jalammar.github.io/illustrated-transformer/
https://jalammar.github.io/illustrated-transformer/
The Final Linear and Softmax Layer
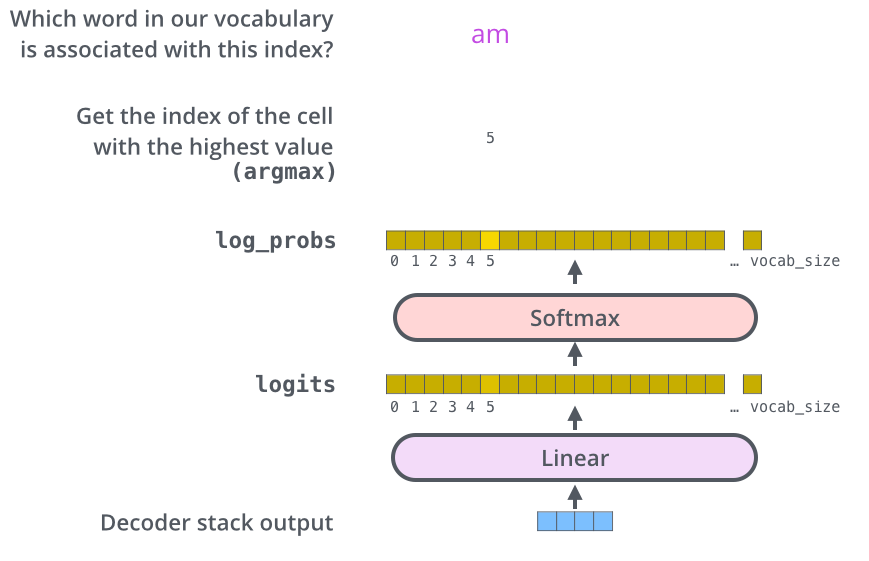
- 마지막의 Linear와 Softmax Layer 를 통해 어떤 확률이 가장 높은 문자나 글자가 나오게 된다.
참고자료
transformer 에 대한 자세한 설명 Jay Alammar블로그
pytorch official trnsformer tutorial
Comments